Audio representation learning (ARL) has seen significant advancements in recent years. The diversity in ARL methods and datasets poses a challenge in systematically comparing their capabilities. To address this issue, we present ARCH (Audio Representations benCHmark), a comprehensive benchmark designed to evaluate ARL methods across diverse audio classification domains, covering acoustic events, music, and speech.
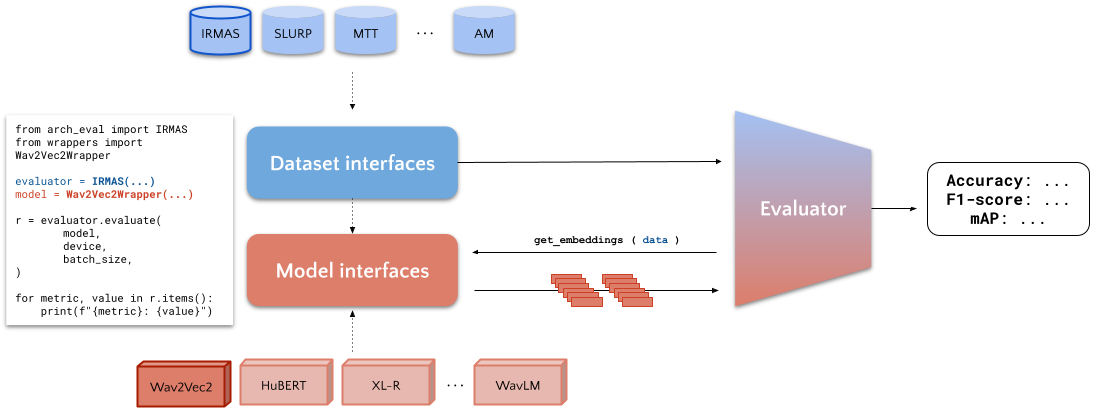
ARCH is designed to be easy to use, providing a unified interface for loading datasets and evaluating audio representations. Researchers can readily access the benchmark and start evaluating their models without the need for complex setup or configuration.
One of the strengths of ARCH lies in its extensibility. Researchers can easily add new datasets, tasks, and models to the benchmark, allowing for the evaluation of a wide range of audio representations. This flexibility enables the benchmark to adapt to evolving research needs and incorporate new developments in the field.
With the proliferation of ARL models and datasets, comparing their performance can be challenging. ARCH aims to standardize the evaluation of audio representations by providing a common framework for assessment. By establishing a standard evaluation protocol, ARCH facilitates fair and consistent comparisons between different methods.
ARCH includes 12 datasets spanning acoustic events, music, and speech domains, each covering single-label and multi-label classification tasks. The benchmark evaluates several state-of-the-art SSL models, including Wav2Vec 2.0, WavLM, HuBERT, data2vec, and XLS-R, pre-trained on diverse datasets such as LibriSpeech, Libri-Light, GigaSpeech, and VoxPopuli. Additionally, ARCH introduces new pre-trained models trained on the AudioSet collection, addressing the lack of open-source models for non-speech tasks.
ARCH follows a standardized evaluation process to assess the quality of learned audio representations. The evaluation protocol involves training a simple linear classifier on frame-level representations generated by the models and measuring performance metrics such as mean average precision (mAP) for multi-label classification tasks and accuracy for single-label tasks.
Extensive experiments conducted on ARCH demonstrate the effectiveness of pre-training models on diverse datasets for learning generalizable representations. Models pre-trained on AudioSet consistently outperform speech-pretrained models on non-speech tasks, highlighting the importance of diverse pre-training data. Increasing model size also leads to performance improvements across all domains, underscoring the benefits of larger model capacities. More information on the benchmark and detailed results can be found in the ARCH paper and on the associated Hugging Face space.
In conclusion, ARCH provides a valuable resource for the standardized evaluation of audio representations across diverse domains. By offering a unified framework, ARCH facilitates fair comparisons between different ARL methods, helping researchers identify optimal models for specific tasks or domains. With its plug-and-play interface, extensibility, and focus on standardization, ARCH aims to accelerate progress in audio representation learning and foster collaboration within the research community.
To explore the ARCH benchmark and access the results, visit the official repository or have an overview of the results on the 🤗 Hugging Face Space.