ACM Multimedia 2022 is a few weeks away and, with my colleagues from Politecnico di Torino, we are setting up the final touches to our presentations. We had the pleasure to work on very interesting research problems during these last months, and we are excited to present some of our findings in Lisboa. This post contains a short preview of what we are going to present.
We all know how annoying mosquitoes can be, but they can also transmit diseases such as malaria, dengue, and Zika. Interested in audio processing, we decided to take part in the Mosquito detection challenge at ComParE 2022. It is one of the grand challenges organized within the ACM Multimedia conference, and the goal is to develop automatic systems that can detect the presence of mosquitoes in audio recordings.
We used a novel transformer-based approach and framed the problem as an audio frame classification task. Our model leverages the Wav2Vec 2.0Baevski, A., Zhou, Y., Mohamed, A., & Auli, M. (2020). wav2vec 2.0: A framework for self-supervised learning of speech representations. Advances in Neural Information Processing Systems, 33, 12449-12460. On arXiv. pre-trained model and predicts whether each frame contains mosquito sounds or not. Looking at our NLP background, we propose different labeling schemes to better exploit the context information within the audio recordings.
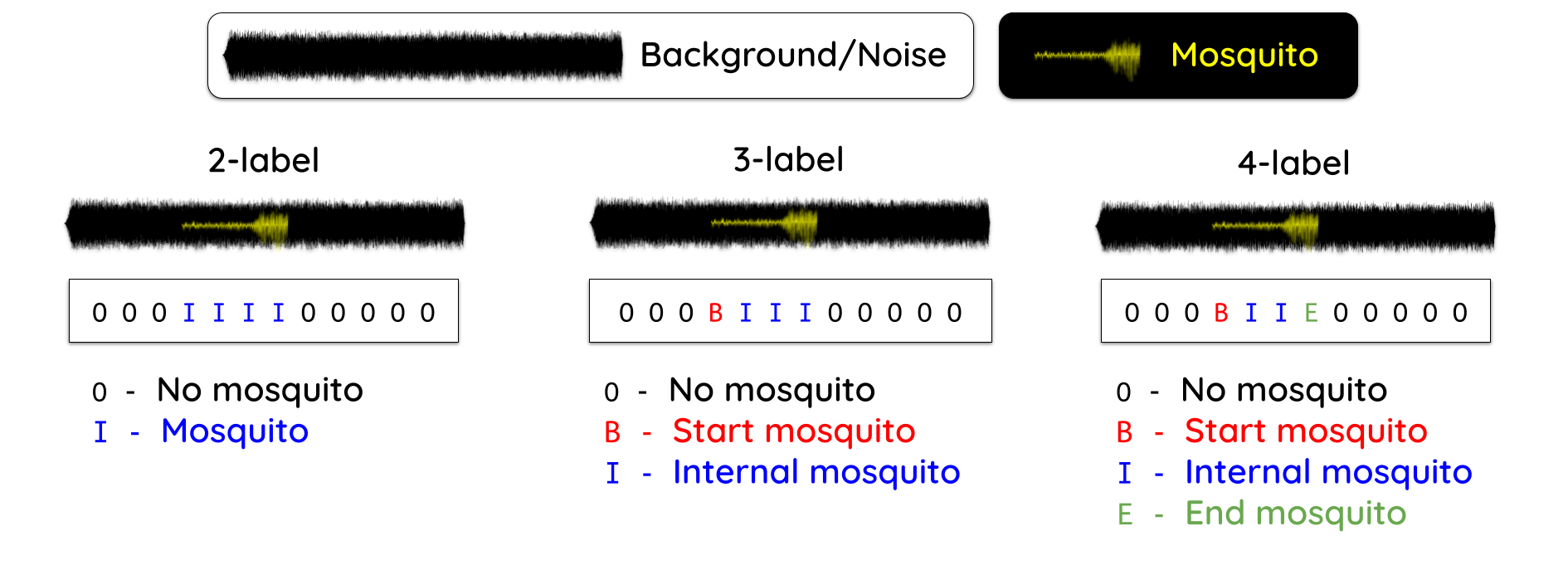
A few takeaways from the results:
A considerable body of research in the field of automatic emotion recognition from speech has been developed in the last years. However, most of the existing systems are designed and trained on a single dataset, usually collected from a specific geographical region, and are not generalizable to other datasets.
In this work, we address the vocalisation challenge at ComParE 2022. It aims at building systems that automatically recognise emotions from short vocalisations. The peculiarity of this challenge is that the training dataset is composed of female-only recordings while the test set includes male-only recordings.
To address the challenge, we propose a transformer-based emotion recognition system that is trained on the challenge’s training set. However, to allow for model portability across different speakers' genders, we augment the training set by using both traditional and neural data augmentation techniques.
Capturing emotions from facial expressions is a challenging task. In this work, proposed for the MuSe 2022 workshop, we propose a novel video-based emotion recognition system that leverages the Perceiver Jaegle, A., Gimeno, F., Brock, A., Vinyals, O., Zisserman, A., & Carreira, J. (2021, July). Perceiver: General perception with iterative attention. In International conference on machine learning (pp. 4651-4664). PMLR. On arXiv. architecture. It is a modality-agnostic architecture that can be used to process different types of data, such as images, videos, audio, and text.
The solution aims at identifying the emotions expressed by a person reacting to a video clip. The input to the model is a video recording of the face of a person watching a video and the output is a vector of probabilities that represent the likelihood of each emotion class. We use the Perceiver to process multiple modalities at the same time and experimented with different combinations of modalities:
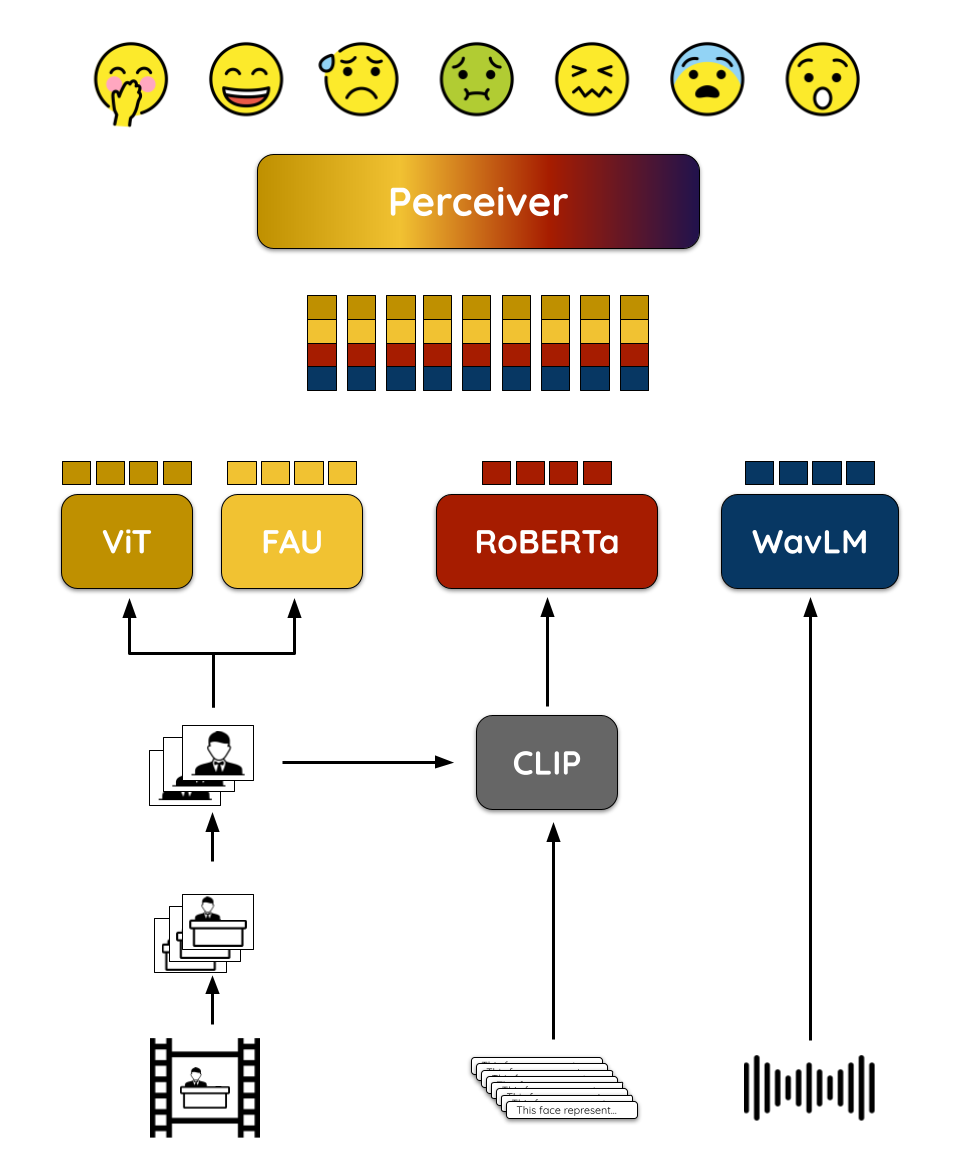
The results shows that combining multiple modalities improves the performance of the model. As expected, the audio modality is the least discriminative, while the FAUs and image embeddings are the most discriminative. Besides being derived from a set of manually-defined templates, the text embeddings shown to be effective for improving the performance of the model.
Full paper here!This post describes three papers that will be presented at the ACM Multimedia 2022 conference. Each of them address a different challenge in the field of audio or multimodal processing. Complete information could be found in the papers that will be linked as soon as they are available. The details of each methodology are described in the papers, while this post provides only a high-level overview of the proposed solutions.
I want to thank my co-authors Lorenzo Vaiani, Alkis Koudounas, Luca Cagliero, Paolo Garza and Elena Baralis for their contributions to this works.